Introduction:
Please send us email for any comments
Tracking file involves the similarity algorithm. In our new launched application, we provide the simple similarity analysis to help to compare two files and show the compare result immediately. In case to keep tracking of file relationship and history, we need to develop a file management application. The file management application is one of our goals to achieve in future.
This article mainly introduces the Similarity Analysis Basic application which supports in Android, iOS, MacOS and Windows OS.
Guided illustration:
The following diagrams illustrate user interface design.
There are only three buttons in this application. There are two “Browser” button allows to browser (pick up) file from the location device (mobile or PC). The “Process similarity analysis” button allows comparison between source file and compare file. In the case of either source file or compare file is empty, the “Process similarity analysis” button is disabled (grey in color). Both source file and compare file is input properly, the “Process similarity analysis” button will be changed to Light Orange color.
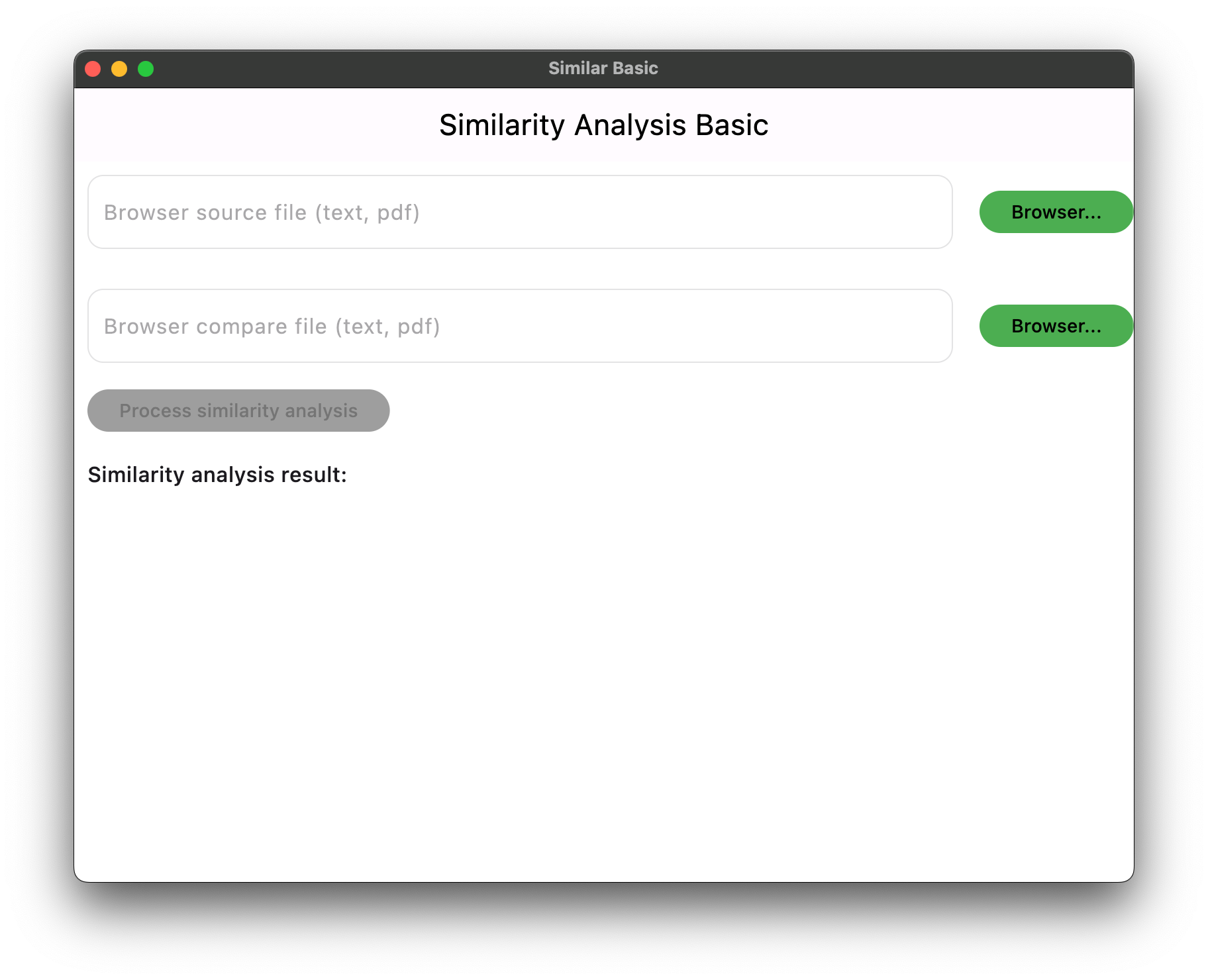
Figure 1. This is the main page of Similarity analysis basic.
When both source file and compare file is input properly, the “Process similarity analysis” button will be changed to Light Orange color. Please be patient to wait for the result. The internal timeout is 10 seconds.
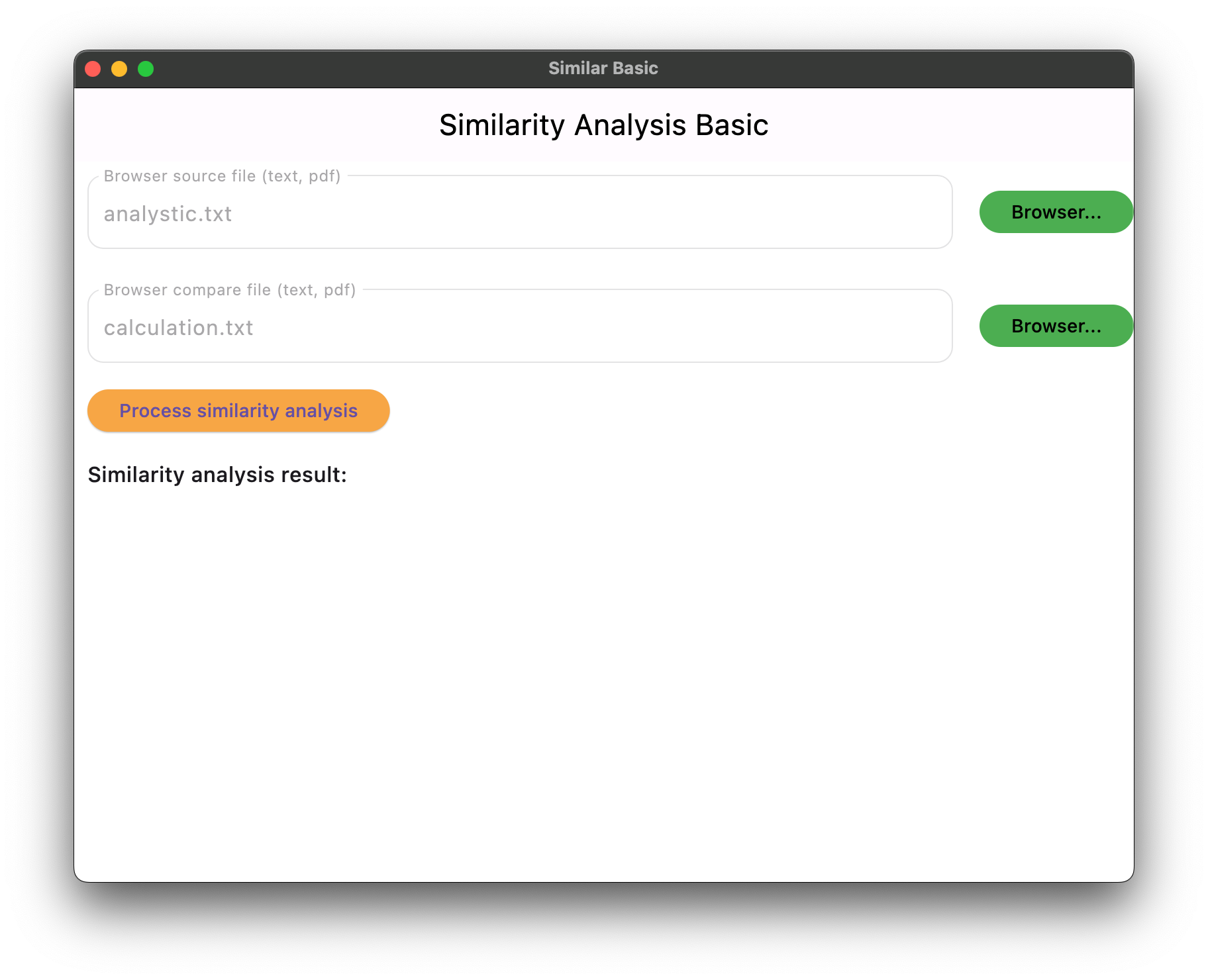
Figure 2. Ready to process the similarity analysis.
Explanation of Similarity analysis result as follows:
- Similarity unique count is a first come first serve algorithm that meant first match content will be treated as unique count.
- Similarity overlap count is a content match in somewhere repeatedly. The overlap percentage more than 100% that meant some patterns (or word or sentence) are more than one occurrence.
- When overlap percentage more than 100%, the similarity percentage more than 50% meant that the content is most likely highly similar and the content in somewhere are repeated.
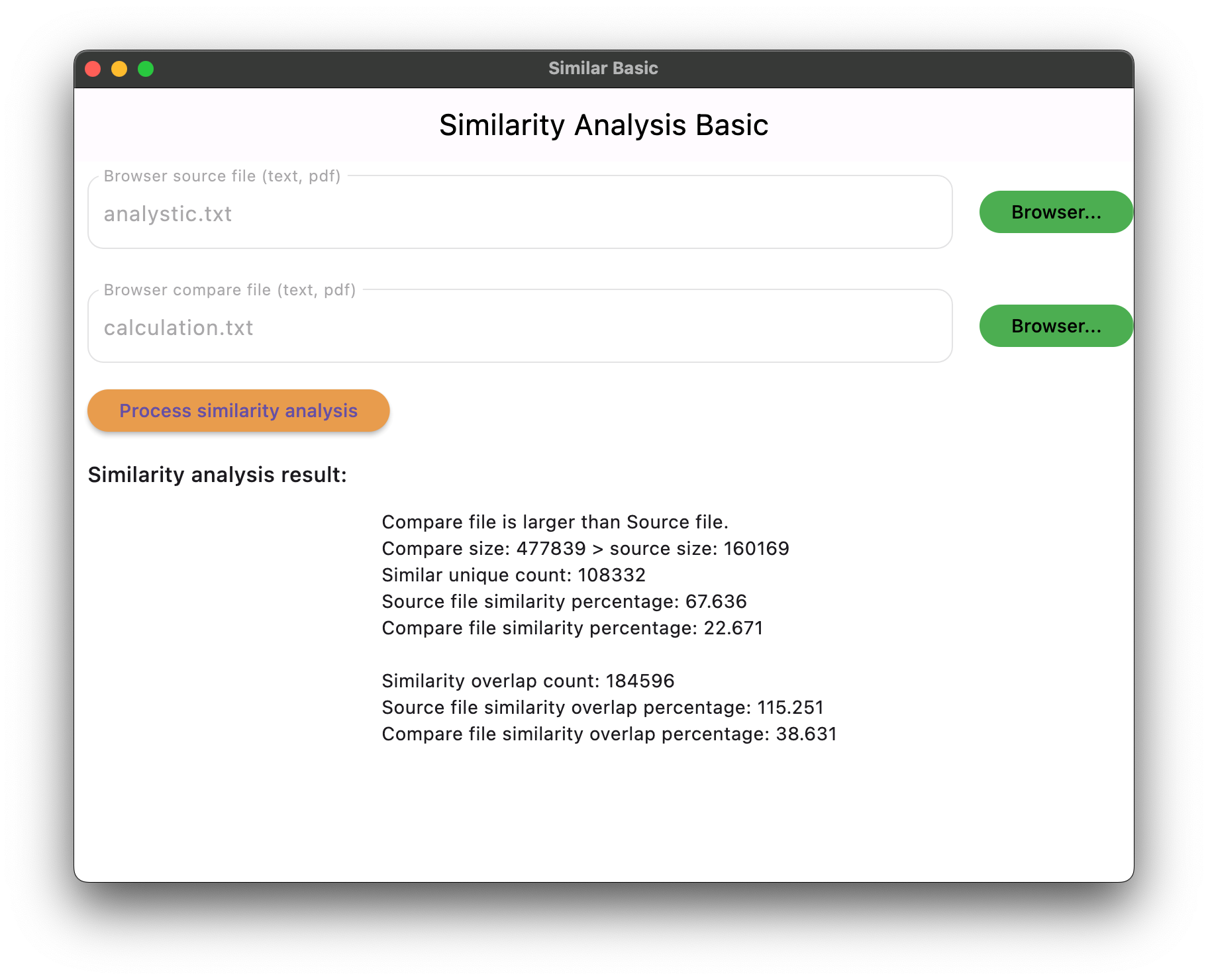
Figure 3. The similarity analysis result of source file and compare file.
Summary:
We provide quick similarity analysis for two input files in the basic version. The application supports pdf and text file, it is no limited to input same file type at the same time.
Similar Plus Demo Video:
Youtube:
Download:
Google Play
Google Play Download:
Similar Plus Microsoft Store Download:
Similar Plus in Microsoft Store
Limitations:
In our PDF extractor, we have a limitation on extracting Microsoft Power Point file (*.pptx) convert to PDF accurately. The major imperfections are the line termination and space. In some cases, the line termination is misaligned. We apologies on this imperfection. We are studying the method and trying to fix this.
We want to support more PDF versions, unfortunately we are lacking resources to achieve this. We will continue to improve our extractor to support more PDF files. In case the file is not sensible and confidential, please contact us and help us to evaluate it. Again, we are apologies on this imperfection.