Positioning Summary
LibDocAnax is a high-performance engine designed for downstream consumption. We extract structured, actionable data from PDF and Microsoft Office documents to power automated data pipelines.
| Product Name | LibDocAnax |
|---|---|
| Supported Formats | PDF, Word, Excel, PowerPoint |
| Core Purpose | System-to-system data extraction |
| Target Markets | Legal, Finance, Healthcare, APAC/MENA |
Native Parsing Focus
Unlike standard OCR tools, LibDocAnax uses native, rules-based parsing for superior reliability in structured workflows.
- Layout-aware text extraction
- Sequential heuristics for columns
- Line-by-line document comparison
- Unicode & CJK First-class support
Enterprise Readiness
Designed to integrate directly with high-scale enterprise environments.
- Batch processing at scale
- SAP, Oracle, & Salesforce Connectors
- AI/LLM Native interfaces planned
- RTL & Arabic Script shaping
Security First Air-Gapped & Local-First Deployment
LibDocAnax is built for regulated industries (Banking, Legal, Government). Our architecture supports fully offline usage and on-premises deployment, ensuring sensitive data never leaves your secure environment.
- No raw text exposure required
- Zero cloud-dependency options
- Compliance-ready for high-security sectors
Technical Specifications
| Feature | Capabilities |
|---|---|
| PDF Parsing | Native, Rules-based (Versions 1.3 - 2.0) |
| Office Parsing | DOCX, XLSX, PPTX Native Support |
| Content Analysis | Word-level & Sentence ranking |
| Language Support | Latin, CJK, Arabic (Mixed multilingual) |
| Extraction | Tables, Forms, and Annotations (On-demand) |
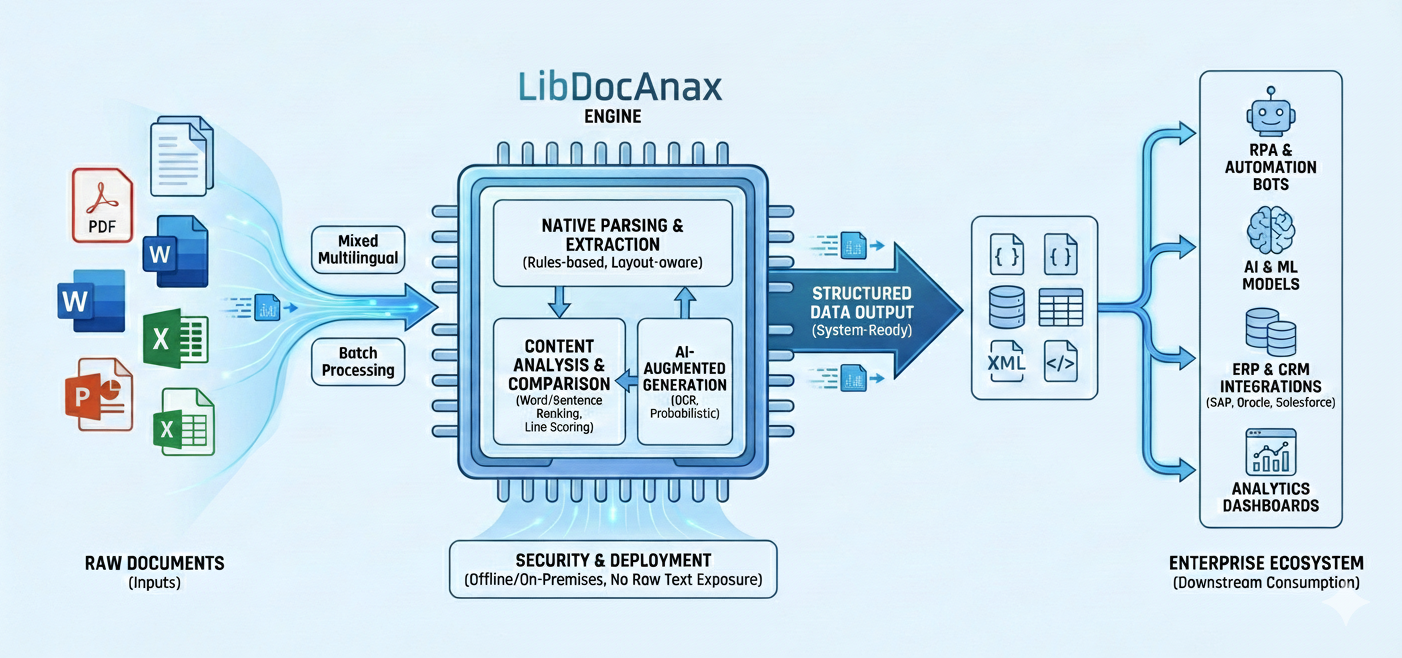
Illustration diagram designed by Nano Banana Pro